线性表的查找
顺序查找
顺序查找(Sequential Search)的查找过程为:从表的一端开始,依次将记录的关键字和给定值进行比较,若某个记录的关键字和给定值相等,则查找成功;否则,若扫描整个表后,仍未找到记录,则查找失败。
顺序查找既适用于线性表的顺序存储结构,也适用于线性表的链式存储结构。
算法如下:
import { List, ListNode } from '../../linear-list/list'
export function sequentialSearch<T>(list: List<T>, key: T) {
let prev: ListNode<T> | null = list.headNode
while (prev && prev.data !== key) {
prev = prev.next
}
return prev
}上述算法使用了 线性表中的链表结构。
平均查找长度为
时间复杂度为
优点
- 简单易实现;
- 对表结构无任何要求;
- 不用关心记录是否有序。
缺点
- 平均查找长度较大,查找效率较低。
总结
当
折半查找
折半查找(Binary Search)也称二分查找,是一种效率较高的查找方法。
查找过程:从表的中间记录开始,如果给定值和中间记录的关键字相等,则查找成功;如果给定值大于或者小于中间记录的关键字,则在表中大于或小于中间记录的那一半中查找,这样重复操作,直到查找成功,或者在某一区间为空,则代表查找失败。
该查找过程可用二叉树来描述。树中每一结点对应表中一个记录,结点值存储对应记录在表中的位置。把当前查找区间的中间位置作为根,左子表和右子表分别作为根的左子树和右子树,由此得到的二叉树称为折半查找的判定树。
折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
算法如下:
export function binarySearch<T>(data: T[], key: T) {
let low = 0
let high = data.length - 1
while (low <= high) {
const mid = Math.floor((low + high) / 2)
if (data[mid] === key) {
return mid
}
if (data[mid] > key) {
high = mid - 1
} else {
low = mid + 1
}
}
return -1
}借助于判定树,很容易求得折半查找的平均查找长度。为了讨论方便,假定有序表的长度
当
时间复杂度为
优点
- 比较次数少,查找效率高。
缺点
- 必须使用顺序存储结构;
- 必须是有序表。
总结
查找前需要排序,而排序本身是一种费时的运算。同时为了保持顺序表的有序性,对有序表进行插入和删除时,平均比较和移动表中一半记录,这也是一种费时的运算。因此,折半查找不适用于数据元素经常变动的线性表。
分块查找
分块查找(Blocking Search)又称索引顺序查找,这是一种性能介于顺序查找和折半查找之间的方法。在此方法中,除表本身外,还需要建立一个索引表。
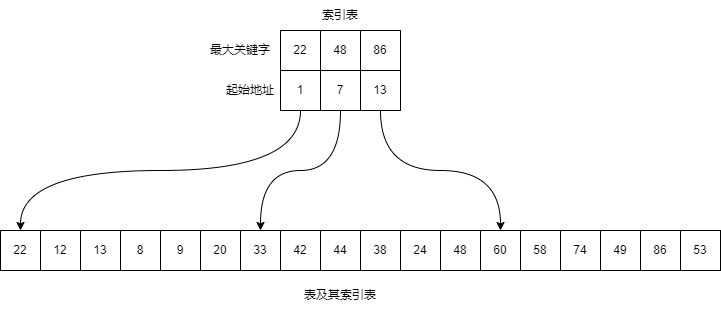
如上图所示,表中含有 18 个记录,可分成 3 个子表
分块有序:第二个子表中所有记录的关键字均大于第一个子表中的最大关键字,第三个子表中的所有关键字均大于第二个子表中的最大关键字,依此类推。
查找过程:先确定待查记录所在的块,然后在块中顺序查找。如果此块中没有关键字等于给定值的记录,则查找失败。
由于索引表是按关键字有序,所以顺序查找和折半查找都可用于确定块,而块中的记录是无序的,在块中只能使用顺序查找。
因此,分块查找算法为顺序查找和折半查找两种的算法的简单结合。
平均查找长度为
一般情况下,为进行分块查找,可以将长度为
若使用顺序查找确定块,则分块查找的平均查找长度为
可见,此时的平均查找长度不仅和表长
若用折半查找确定块,则分块查找的平均查找长度为
优点
在表中插入和删除元素时,只要找到该元素对应的块,就可以在该块内进行插入和删除运算。由于块内是无序的,故插入和删除比较容易,无需进行大量移动。
缺点
- 要增加一个索引表的存储空间;
- 需要对索引表进行排序。
总结
如果线性表既要快速查找又经常动态变化,可以使用分块查找。